
Justin Barry
ML research engineer & applied scientist building intelligent systems
Former Applied Scientist @ Amazon • MS Computer Science • BS Math+CS
Machine Learning Applied Scientist and Research Engineer. Former Amazon ML Scientist (Prime Video).
I design and ship machine learning systems—generative and discriminative—across vision, language, and structured data. I own the math and the PyTorch. I build architectures from first principles when off-the-shelf fails, and I build agentic systems: multi-agent LLM pipelines that generate, critique, and rank.
My edge is messy problems. When baselines don't work and the objective isn't obvious, I turn ambiguity into a clear loss function and a system you can deploy.
I work remotely as an embedded research engineer—either as a full-time hire or via my LLC on longer-term engagements and scoped projects.
Featured Project
Joint Image+Text Rectified Flow Training Loop
Building a joint image and text Rectified Flow model from scratch in PyTorch. This video walks through the complete training loop implementation, demonstrating the mathematical foundations and practical engineering of modern generative models.
Experience
Industry experience at scale
Machine Learning Consultant
IndependentRemote
Machine Learning Content Creator
YouTube Channel: @JustinTheJediRemote
Senior Machine Learning Scientist
SpotterLos Angeles, CA
ML Consultant
IndependentRemote
Machine Learning Scientist
AmazonSeattle
Senior Software Engineer
CSRA IncWashington, DC
Technical Deep Dives
Building advanced ML architectures from first principles
NanoGPT from scratch in PyTorch
Complete implementation of a GPT-style transformer language model, covering attention mechanisms, positional encodings, and autoregressive training.
CLIP from scratch in PyTorch
Building OpenAI's CLIP model from the ground up—dual encoders for vision and language with contrastive learning objectives.
Vision Transformer from scratch in PyTorch
Building the Vision Transformer (ViT) architecture—patch embeddings, transformer blocks, and classification heads for image recognition.

Rectified Flow for Image in PyTorch: Train Loop (Part 1)
Complete PyTorch implementation of Rectified Flow for image generation—building the model architecture, training loop, and sampling process from the ground up.
Stable Diffusion XL Objective Function Derivation
Mathematical derivation of the SDXL training objective, from variational lower bounds to practical noise scheduling strategies.
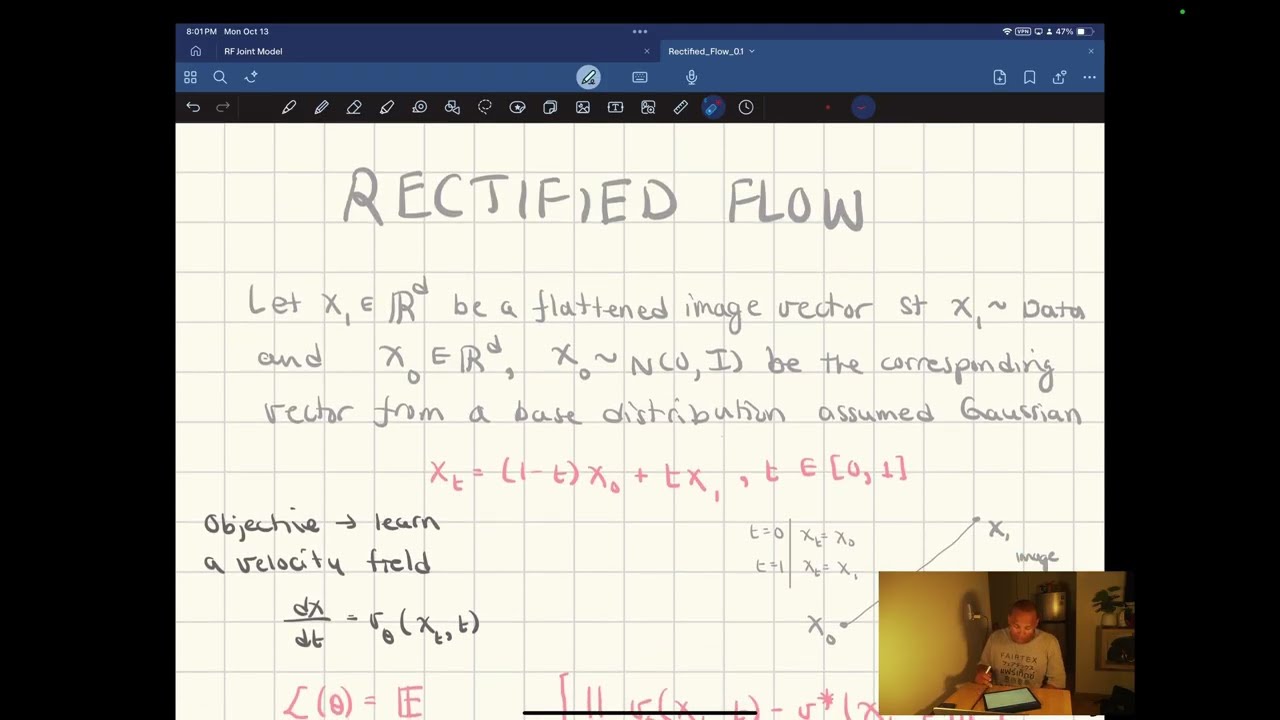
Rectified Flow objective explained
Mathematical breakdown of the Rectified Flow training objective for generative models—from continuous normalizing flows to practical implementation.
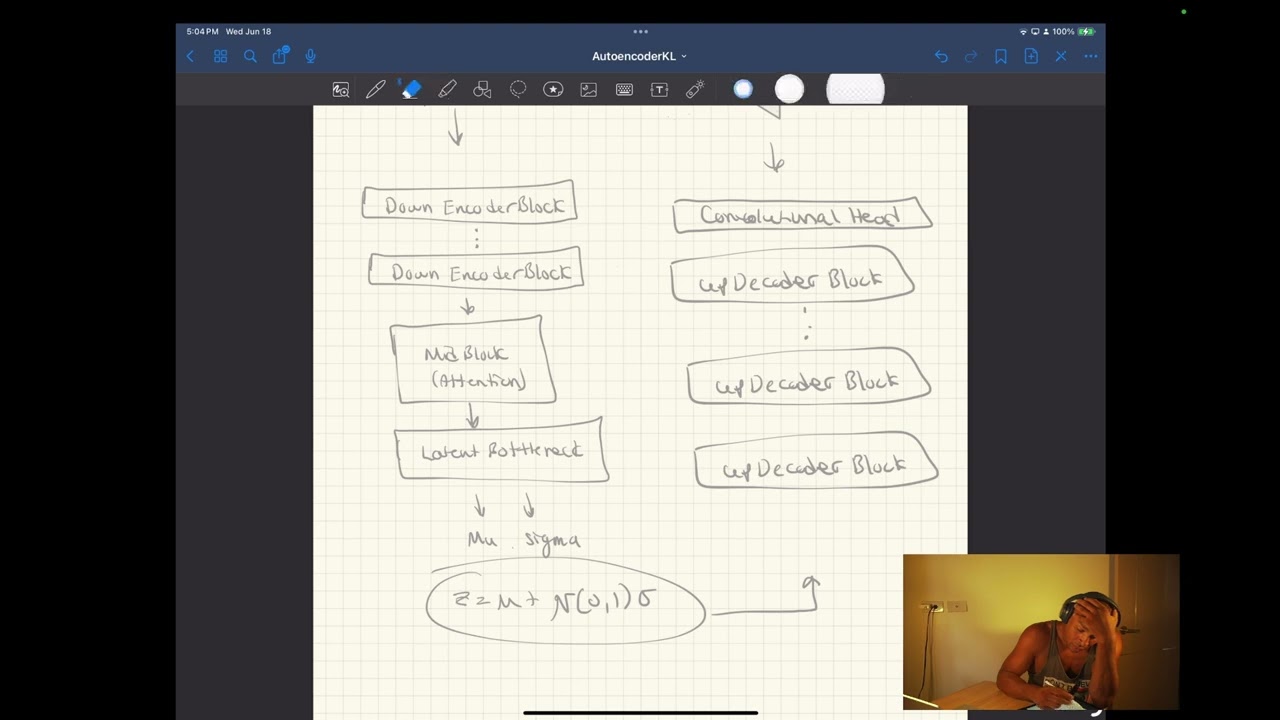
AutoencoderKL from scratch in PyTorch
Implementing the KL-regularized autoencoder used in latent diffusion models—encoder, decoder, and KL divergence loss.
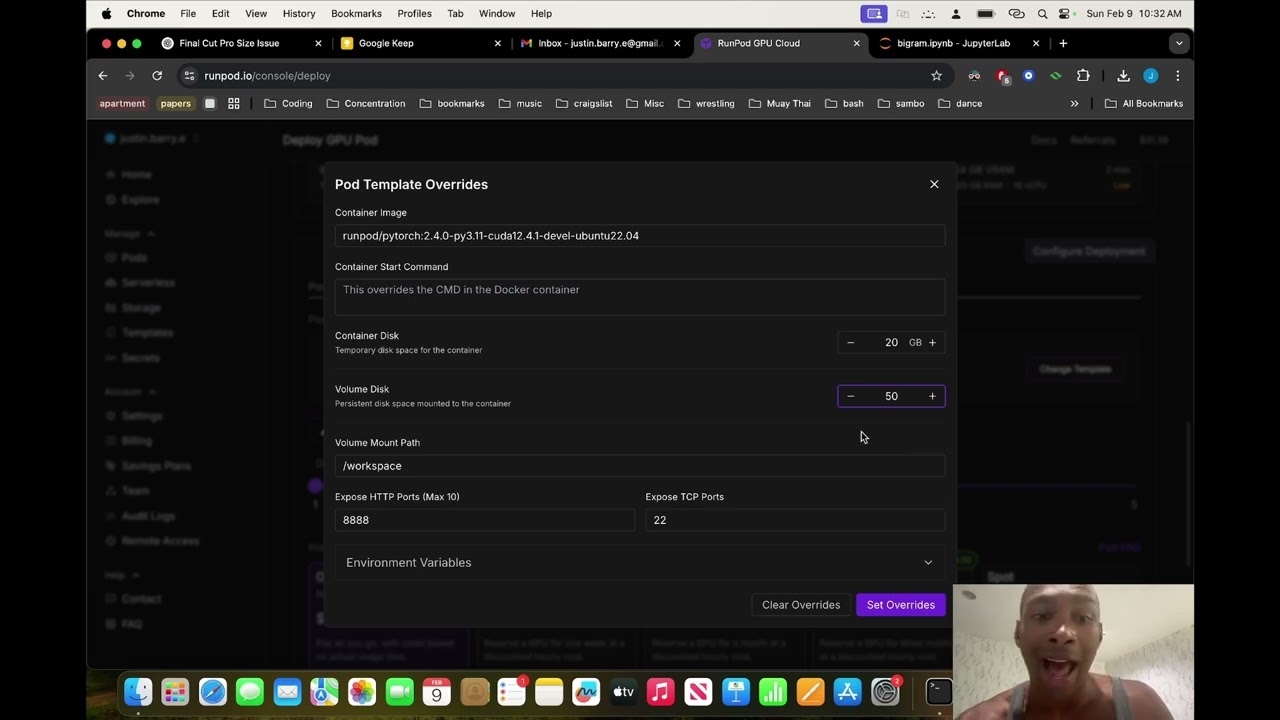
Deploying and training NanoGPT on Runpod
Practical guide to deploying GPT models on cloud infrastructure—setting up training pipelines, managing compute resources, and monitoring experiments.
Education
MS in Computer Science
(former PhD track)University of Central Florida
BS in Mathematics and Computer Science
Dual Major
Christopher Newport University
GEM Fellowship
National GEM Consortium