Designing a Deterministic LLM Agent
TLDR
A coding agent is a stochastic model wrapped in a deterministic scaffold. The scaffold is where engineering lives.
- An LLM is stochastic. An agent is an LLM constrained by a deterministic driver.
- The driver's job is to enforce invariants, bound capabilities, and create an audit trail.
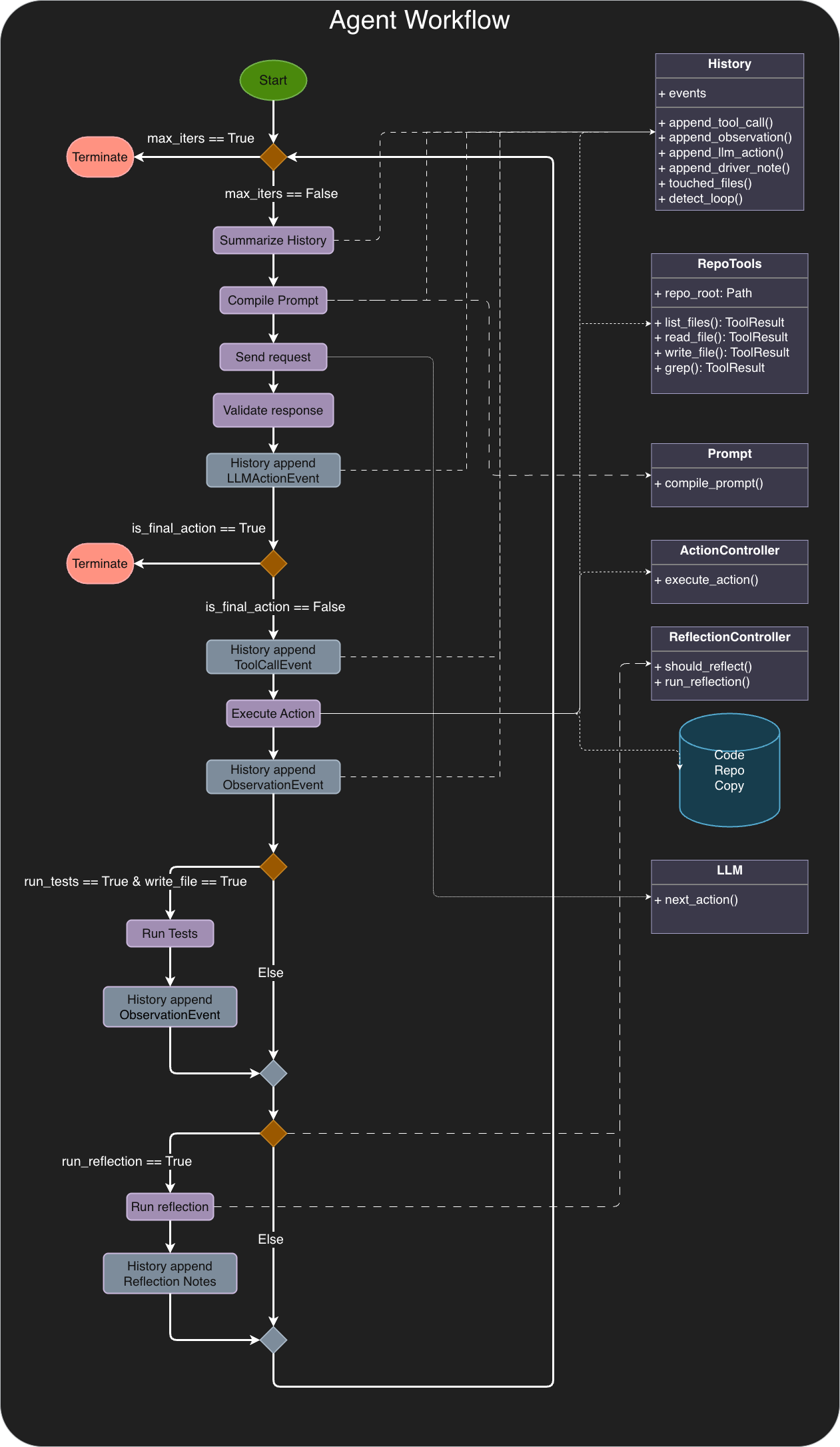
- This post walks through how llm-repo-agent does that with a ledger-style History, derived summaries, allowlisted tools, driver-owned tests, and reflection triggers.
Table of Contents
- Workflow Diagram
- What this is
- Architecture at a glance
- The control loop
- Engineering choices
- How it evolved
- Mapping to agent fundamentals
- Limitations and next steps
What this is
llm-repo-agent is an agentic program that can inspect a code repo, make edits, and run unit tests to verify correctness. More generally, it can pursue a goal as long as the provided tools are sufficient.
The problem: LLMs can propose edits, but they can't observe a repo or verify outcomes without an external oracle (tool output/tests).
The solution: use an LLM as a stochastic reasoning engine, then wrap it in deterministic scaffolding that constrains outputs and drives the workflow toward the goal.
Concretely: the program takes a path to a local repo, a text goal, and a test command to run inside the target repo. It can then modify files and return a summary of changes plus test results.
Example invocation:
poetry run repo-agent \
--repo ~/projects/QuixBugs \
--goal "Fix quicksort so python_testcases/test_quicksort.py passes. Make the smallest correct change." \
--trace runs/quixbugs_trace.jsonl \
--test "python -m pytest -q python_testcases/test_quicksort.py"
Example output:
Fixed quicksort by changing the partition conditions to use '<' for lesser and '>=' for greater to correctly sort duplicates. All tests pass now.
Tests: PASSED - All tests passed.
Output snippet: ............. [100%]
Architecture at a glance
Driver (RepoAgent.run) — owns the loop and enforces invariants (max_iters, when tests run, when reflection runs).
If the LLM is a stochastic "brain," the driver is the scaffold that enforces rules:
- loop structure
- when tools run
- when tests run
- when reflection runs
- how memory is summarized and passed forward
- max-iteration stopping
Driver invariants
Invariants are properties the system keeps true no matter what happens inside the loop—even when the LLM is wrong, noisy, or unpredictable.
They're how you get determinism and reliability out of a system that contains a stochastic component.
Invariants enforced in this implementation:
- Typed action contract: only
ToolCallActionorFinalAction. - No final before evidence: don't allow a final response until at least one observation exists.
- Tool allowlist: only
list_files/read_file/write_file/grep(no arbitrary shell). - Driver-owned tests: only the driver runs
test_cmd, and only afterwrite_file. - Reflection gate: only on loop/tool failure/test failure.
- Bounded run: stop after
max_iters.
LLM adapter (LLM, OpenAIResponsesLLM) — turns prompts into typed Actions.
The adapter sits between the LLM API and the agent. OpenAIResponsesLLM sends the prompt, then parses the response into Actions that the rest of the system knows how to execute.
Actions (ToolCallAction, FinalAction) — the contract between model intent and system execution.
LLMs generate tokens autoregressively, which means outputs are unconstrained by default. This agent constrains the model output into a typed action schema, and the driver enforces it. The system prompt instructs the model to return either a ToolCallAction or a FinalAction as a single JSON object, which the driver parses into the corresponding class.
History — model-facing ledger (working memory).
At start, the model only has the goal and a repo path. It usually needs multiple investigation steps before it can act correctly. History is an append-only event list containing what happened so far:
- tool calls
- tool observations
- driver notes (loop/parsing)
- reflection notes
- test results (recorded as an observation)
History provides context so the model can make the next decision.
RunSummary — derived snapshot used to compress History and stabilize prompts.
Each iteration, the driver derives a compact summary from History and passes it into the prompt. This keeps prompts stable and avoids carrying the entire event stream.
RepoTools + Controller — allowlisted deterministic operations (list_files, read_file, write_file, grep).
Tools are implemented in Python as a small allowlist of repo operations. The agent can't run arbitrary shell; only the driver can optionally run the configured test command via subprocess.run.
RepoTools defines the tool implementations. ActionController sits between the agent and the tools and dispatches tool calls on the agent's behalf.
Reflection Controller — triggers and runs reflection, then persists notes.
This component decides whether to execute reflection and encapsulates the logic for dispatching the reflection request and appending the resulting notes back into History.
Trace — human-facing JSONL audit log (debug/replay), not fed to the model.
Trace is a replay log of the run. It exists for debugging and accountability, not memory. Trace is written to JSONL so you can inspect runs by run_id.
The control loop (the driver)
Figure 1 is the primary reference for the control flow. Below is the same flow in words, focusing on what the driver enforces.
1. Prior to entering the loop
The driver runs a bounded loop for max_iters. The program takes goal, repo_path, trace_path, and an optional test_cmd, then iterates until it either completes successfully or hits max_iters.
2. Pre action request
Derive RunSummary from History; compile prompt; send.
The driver compiles context for the next model call:
- History (or a window of it)
- a derived RunSummary (current "state of affairs")
- available tools and the action schema
3. Response validation
Parse exactly one JSON object → typed Action.
The driver parses the model response and enforces the action contract: it must become either a ToolCallAction or a FinalAction.
4. Execute Action
If tool: append tool call; execute allowlisted tool; append observation; log Trace.
- The driver appends the model's action to History.
- If the action is a tool call,
ActionControllerdispatches the corresponding allowlisted tool. - The tool result is appended to History as an observation and logged to Trace.
If the action is FinalAction, the driver prepares to exit (subject to invariants like "no final before evidence").
5. Run tests?
After write_file, driver optionally runs tests; append observation.
To know whether a change worked, the agent needs an oracle—an external signal like tool output or a test run.
If the model calls write_file and the user provided a test_cmd, the driver runs it and appends the result as an observation. The model is not given a run_tests tool; test execution is driver-owned.
6. Reflection
If triggered, run reflection; append reflection notes.
Reflection (in the sense of the Reflexion line of work) is a second model call used as a postmortem. In this system, reflection is triggered only when:
- a loop event is detected,
- a tool call fails, or
- a test fails.
Reflection notes are persisted into History so they can influence subsequent steps.
Engineering choices
This section explains the decisions that make the system predictable and debuggable.
History as a ledger; summary as a derived view
History is the source of truth: it records what happened in the environment and what the agent observed. RunSummary is derived from History and passed to the model each iteration so it can reason about what to do next.
Key rule: History is append-only. RunSummary is computed from History, not separately mutated.
Small tool surface; no arbitrary shell
The tool boundary is intentionally small (list_files, read_file, write_file, grep).
- Problem it solves: fewer footguns and failure modes; more predictable plans; easier observability.
- Invariant it enforces: every new tool expands the trusted computing base (permissions, timeouts, error semantics, logging, tests).
- Practical benefit: v1 is easier to build and reason about.
Driver-owned tests
The driver controls if/when the test command runs.
- Problem it solves: prevents expensive or repeated test runs as a model failure mode.
- Invariant it enforces: only the driver can run
test_cmd. - Practical benefit: one less tool means one less decision point and one less surface area to harden.
Observability: separate Trace from History
History is for decisions. Trace is for accountability.
- Problem it solves: avoids polluting model context with logging noise.
- Invariant it enforces: Trace is for debugging, not memory.
- Practical benefit:
RunSummaryis easy to derive from History.
Reflection is gated
Reflection is triggered only on loop detection, tool failure, or test failure. Reflection notes are appended to History so future steps incorporate what was learned.
How it evolved
This didn't start as a clean architecture. It started as "generate a repo agent," and what came back was a messy-but-working skeleton.
The refactor wasn't about making it prettier. It was about making it trustworthy: explicit boundaries, enforceable invariants, and an audit trail I could debug.
The key refactors
- Hardened the LLM boundary: enforce exactly one JSON object per model response; log trailing junk; retain raw payloads for debugging.
- Replaced dictionary soup with typed Actions: the loop only handles
ToolCallActionorFinalAction. - Made History the ledger: append-only events (tool calls, observations, driver notes, reflection notes).
- Derived
RunSummaryfrom History: prompt context is computed, not a mutable "state" that can drift. - Split History from Trace: History is model-facing memory; Trace is human-facing replay/debug.
- Kept tests driver-owned + reflection gated: tests run deterministically after
write_file; reflection only triggers on loop/tool/test failures and is persisted back into History. - Moved action + reflection handling into controllers: reduced driver-loop spaghetti.
- Moved prompt construction into a class: prompts aren't assembled ad hoc mid-loop.
Net effect: it went from "a demo I couldn't fully reason about" to "a deterministic driver around a stochastic model that I can debug, test, and explain."
Mapping to agent fundamentals: the Agentic AI Framework
A common decomposition of agentic systems maps well onto this project:
- Control loop (ReAct): Think ↔ Act ↔ Observe. In this repo-agent, that's the driver loop alternating between a typed Action, a tool execution, and an appended observation.
- Reasoning trace (CoT): intermediate reasoning (kept internal or lightly exposed). Here it shows up as the model's "thought" fields that help it choose the next tool call.
- Retrieval (RAG-ish): pull missing facts from the environment. In this v1, "retrieval" is just deterministic repo inspection via
grepandread_file—no vector DB needed yet. - Memory: short-term working memory plus a compressed view. That's
History(append-only ledger) +RunSummary(derived snapshot). - Self-improvement (Reflexion): postmortem notes that persist across steps. Here, reflection only triggers on loop/tool/test failures, and the notes are appended back into History.
- Verification: ground-truth signals (tests/tool outputs). In this system, tests are the main oracle, and the driver owns when they run.
Limitations and next steps
This is a deliberately scoped v1. If I were pushing it toward something I'd trust for broader use, I'd add:
- Diff-aware writes: generate/preview patches (and maybe require the driver to apply them) instead of blind full-file writes.
- Better summaries: include "what I tried / what failed / what I believe now" so the model and the human both get a tighter narrative.
- Stronger eval harness: beyond "run tests after
write_file," add targeted checks, timeouts, and per-goal evaluation rules. - Retrieval index: optional indexing for larger repos (still grounded in deterministic tools, just faster/cheaper to fetch context).
- Budgets + rate limits: caps on tool calls, bytes read, and total runtime to prevent runaway behavior.
- Unified event model: make History + Trace share a single serializable event schema end-to-end.
[1] ReAct: Synergizing Reasoning and Acting in Language Models
https://arxiv.org/abs/2210.03629
[2] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://arxiv.org/abs/2201.11903
[3] Reflexion: Language Agents with Verbal Reinforcement Learning
https://arxiv.org/abs/2303.11366