JanusFlow
Janus Flow Paper: https://arxiv.org/abs/2411.07975
Reader Note: This blog post covers JanusFlow. The goal is less about summarizing the paper and more about explaining the concepts that I had to double-down on in order to grasp. You should read the original paper first. Any summarizations I do will be in service of those explanations.
Thesis
The power of JanusFlow is in unifying two tasks, 1) image understanding and 2) image generation, into a single model while leveraging the semantics of a pretrained LLM as the shared backbone. This multi-task setup on a shared backbone increases robustness and makes the model more "efficient and versatile".
Tasks
-
Image understanding: (Image, text) -> text
Ex: Pass in an image with a question and receive an answer, VQA -
Text conditional image generation: (text) -> image
Ex: Pass in a prompt and generate an image
What makes it unique?
- First to train rectified flow (RF) using an LLM as backbone (diffusion on LLM backbones has been done, but not RF specifically)
- Separate image encoders for understanding vs generation—this turns out to matter a lot for performance
- No complex architectural modifications: adaptations happen outside the LLM backbone
- Deliberate training sequence with specific frozen/unfrozen choices at each stage
Architecture
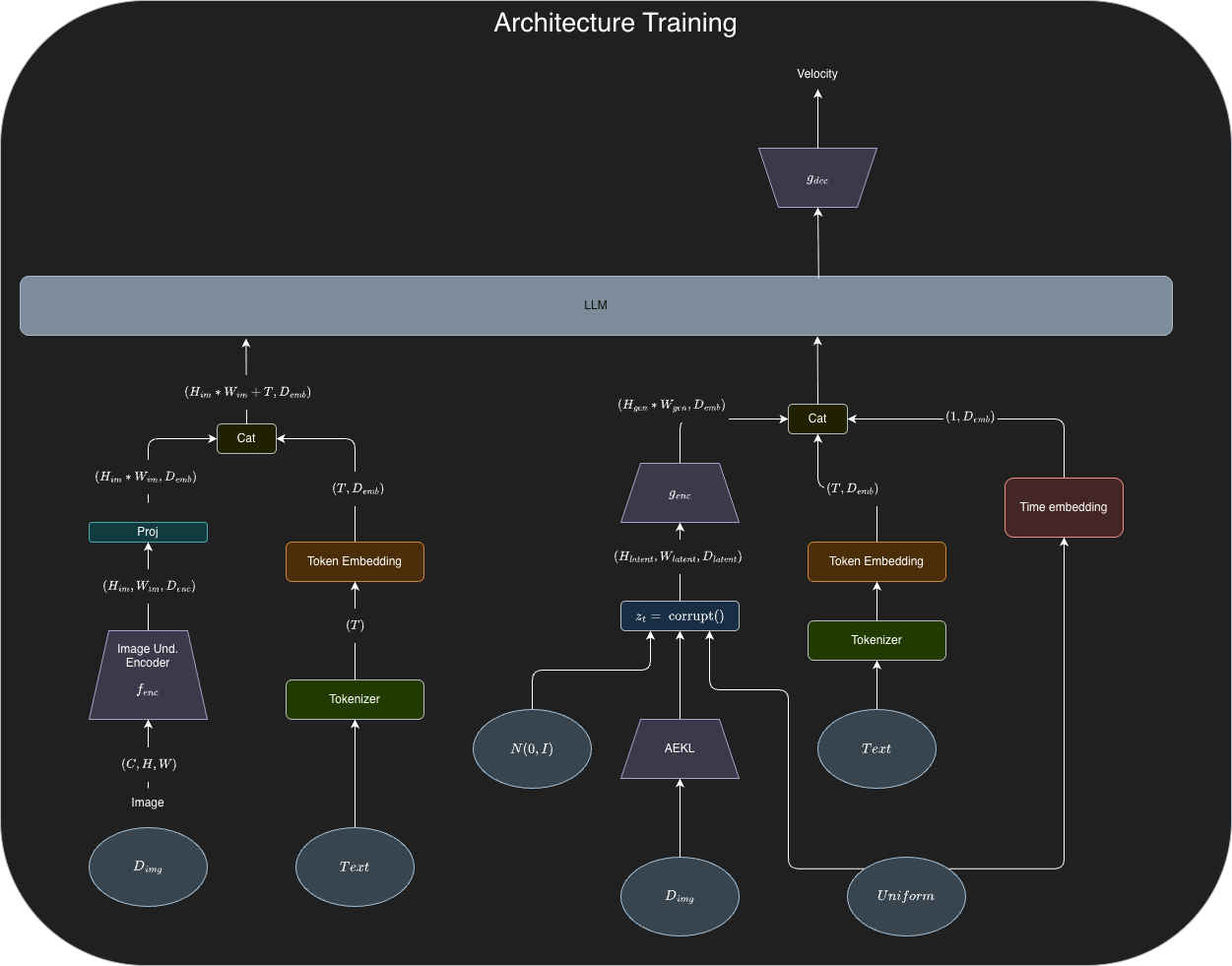
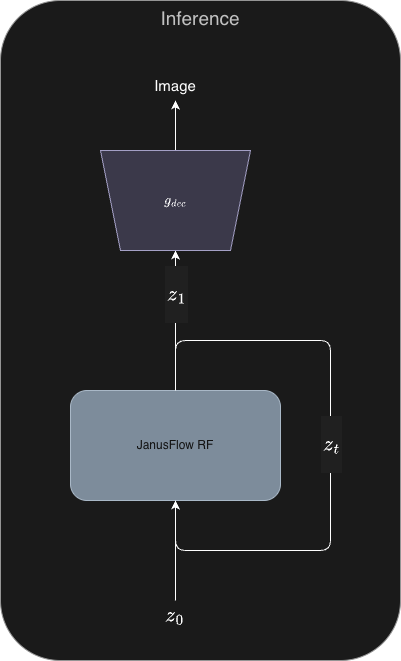
Specifics
Backbone: DeepSeek-LLM 1.3B
: 2x2 patchify layer -> two ConvNeXt blocks -> linear projection layer
: 2 ConvNeXt blocks -> pixel-shuffle layer -> upsample -> linear projection layer
: SigLIP-Large-Patch/16
Training Setup
In each stage, AutoencoderKL is always frozen.
Stage 1 Adaptation: Train only the adapter layers so the LLM learns to interpret image inputs. Everything else stays frozen.
Stage 2 Unified pretraining: Train the entire model except the visual understanding encoder . See "Data" section for what's included.
Stage 3 SFT/instruction-tuning: Fine-tune for task-specific instructions in both MMU and image generation. Here we finally unfreeze (the understanding encoder) to let it adapt to specific task requirements.
Data
Stage 1 & 2
-
Multimodal Understanding Data
- image caption data: "<image> generate the caption of this picture <caption>"
- charts and tables from DeepSeek-VL
- task data: ShareGPT4V for question answering
- interleaved text-image data
-
High-quality images captioned by multimodal understanding models, formatted as "<prompt><image>"
-
Text-only data
Stage 3 SFT
- Multimodal Instruction Data: instruction tuning data
- Image Generation Data: text-image pairs -> "User: <user prompt> \n\n Assistant:<image>"
- Text-only data
Representation Alignment Regularization
This is a clever piece of technology.
is the target image. is the encoded representation of that target via the understanding encoder—a pretrained and frozen SigLIP/16 (hence stop_grad). It acts as the teacher here.
pulls the internal hidden-state features from the LLM after the 6th transformer block during a generation forward pass. The input to the LLM at this point includes the noisy image-latent tokens plus text conditioning plus a time embedding. Think of as a selector that grabs the intermediate representation at a specific layer.
They pass through a small MLP to project it into the same channel dimension as the understanding encoder's feature space , reshape it to a spatial map, and compute cosine similarity with . Gradients flow through and back into the LLM, but not into .
The goal: make the LLM's intermediate states during generation look like the understanding encoder's representation of the target image. Project the intermediate state into the encoder's embedding space, compute similarity, backprop through the projection into the LLM weights. The teacher stays frozen throughout.
The full generation loss:
Since has a negative sign in front of the similarity term, minimizing the total loss means minimizing the RF loss (predicted velocity should match true velocity) while maximizing the similarity (generation-side features should align with understanding-side semantics).
The paper says "all three objectives are applied across all training stages," though I'm not quite sure how the understanding encoder is trained using stop_grad in Stage 3: SFT, which explicitly states the understanding encoder is to be unfrozen here. Or maybe it's just that only the gradients from are sent to and not the gradients from .
If were updated by REPA gradients, you'd have a moving target problem—the teacher drifts as the student learns to match it. Keeping the REPA side frozen while allowing AR gradients through gives you a stable alignment signal plus task-specific adaptation.
Rectified Flow Objective
Why the Shared Backbone Matters
Starting from a pretrained LLM backbone does two things at once.
First, language priors become the control system. The backbone already has strong representations for semantics, composition, instruction-following, and long-range dependencies. JanusFlow teaches that same backbone to treat image-latent tokens as another kind of sequence it can reason over—for understanding via autoregression, and for generation via rectified flow.
Second, the LLM becomes the velocity-field network for RF. During generation, the LLM predicts a velocity field in SDXL-VAE latent space (through the head), conditioned on text tokens and a time token. You then integrate with Euler steps and decode with the VAE. The LLM handles high-level semantic control and global coherence; the VAE latent space plus the generation adapters handle low-level image statistics.
To make this transfer work, you need:
- Generation adapters to translate between VAE latents and LLM-token embeddings—otherwise the LLM can't process the image latent at all
- Unified training across both tasks, so the LLM weights learn to support both regimes
- REPA to keep generation-side representations grounded in understanding-side semantics
What training both tasks on one backbone actually gets you
One set of weights for both modalities. The same internal representation space handles reading/answering about images (AR) and steering generation (RF velocity prediction). The model can reuse its instruction-following and compositional capabilities for generation instead of treating generation as a separate system.
Parameter efficiency. One model, two tasks. Obvious deployment wins.
Cross-task regularization, but only with the right interference prevention. Sharing a backbone can improve generalization, but it can also cause task interference. JanusFlow addresses this directly: separate vision encoders for understanding vs generation to prevent interference, plus REPA to align generation features to the understanding encoder's semantic space. The ablations show this combination improves generation quality when sampling from new random noise + text conditions at inference.
The robustness benefit comes from the specific combination: shared backbone + anti-interference architecture + alignment loss. Not from multi-task training alone.
No significant sacrifice on either task. The ablations show the unified model performs close to understanding-only and generation-only baselines trained under the same conditions.
Evaluation
My main question after understanding the architecture: does this model offer better prompt adherence than SDXL, given its shared LLM backbone? The authors measure semantic accuracy via GenEval and DPG-Bench. Their results show JanusFlow outperforms the competition on these semantic accuracy benchmarks.
Ablation Studies
The ablations validate three design choices:
- Decoupling visual encoders (separate encoders for understanding vs generation)
- REPA is effective (representation alignment improves generation quality)
- Unified training doesn't hurt either task (comparison with MMU-only and generation-only models trained under identical conditions)